- SQLServer基础
1. SQLServer基础
关键字:
- 属性:表中的列也称为数据表的属性。
- 主属性:又称主键或主关键字。所谓主键是指能够唯一标识表中每一行的列或者列的组合。主键中不允许输入重复值和空值,它能使表中不产生重复记录。
- 非主属性:表中除了主属性之外的其他属性。
- 公共关键字:两张数据表共有的字段被称为公共关键字。
1.1. 范式(NF)
范式是“符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”。
晦涩难懂,暂且简单理解成"一张数据表的表结构所符合的某种设计标准的级别。"
1.1.1. 1NF一范式
定义为:符合1NF的关系中的每个属性都不可再分。
现在使用的关系型数据库管理系统都已在创建数据表是要求满足一范式。
不符合1NF的表也无法录入到数据库,如果不符合这个最基本的要求那么操作是无法成功的。
对于下表中的进货和销售还可以继续拆分,对于这样的记录是无法录入到关系型数据库的。
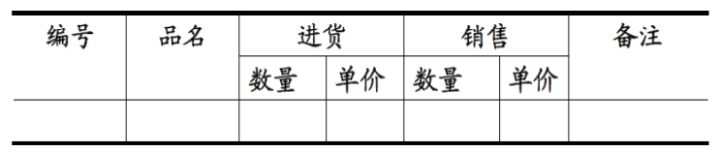
数据库中正确的反应应该如下:

1.1.2. 2NF二范式
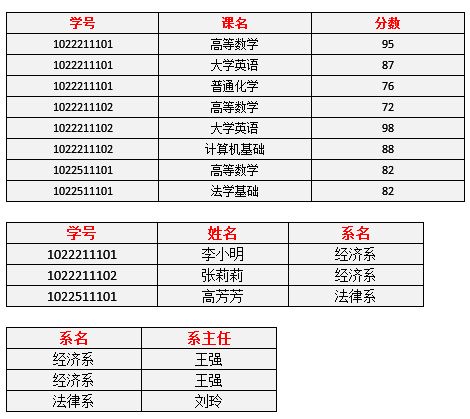
仅仅符合1NF的设计,仍然会存在数据冗余过大,插入异常,删除异常,修改异常的问题等。
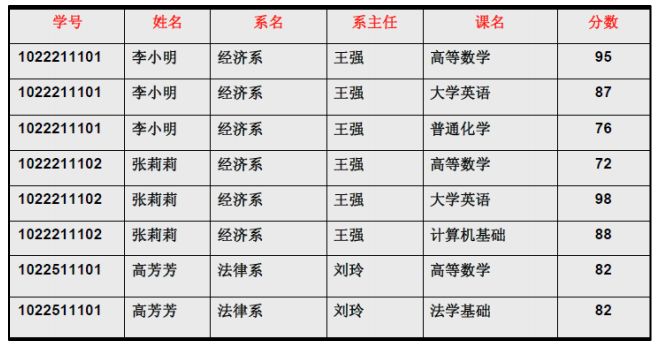
【学号】+【课名】->【分数】
【学号】->【姓名】
【学号】->【系名】
【学号】->【系主任】
针对上表中的数据,存在以下问题:
- 每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次。数据冗余
- 假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的。 插入异常
- 假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。 删除异常
- 假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。修改异常
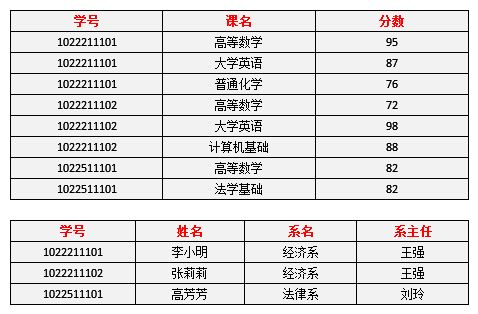
2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。
为了可以区分上表中每一条记录,我们需要结合两个字段才能确定唯一一条记录,即【学号+课名】,在这里【学号+课名】是上表的码/主属性。
关于部分依赖,比如非主属性【姓名】完全依赖于【学号】,与【课名】并无直接关系,即【姓名】与码是部分依赖。
按照2NF进行拆分,解决非主属性部分依赖主属性的问题,如下两张表是符合2NF的:
1.1.3. 3NF三范式
对于上面2NF案例中的学生表,还存在一些问题,【系主任】是完全依赖于【系名】,但在表中【系主任】还依赖于学生【学号】。

3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
存在非主属性【系主任】对于【学号】的传递依赖,上表并不符合3NF的设计。
进一步修改,得到如下依赖关系:
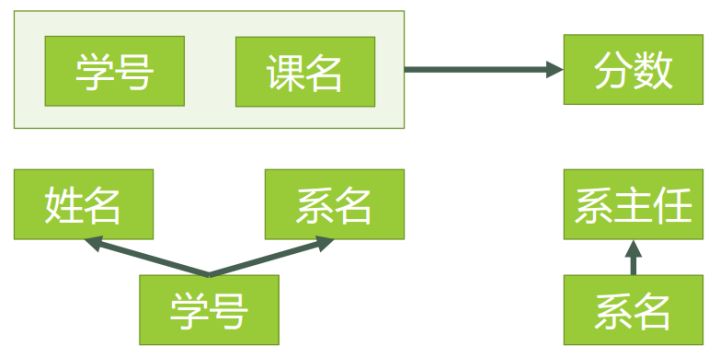
符合3NF的表结构:
1.1.4. BCNF范式
TODO。。。
1.2. 语句
1.2.1. 创建数据库
CREATE DATABASE [TEST_DB]
1.2.2. DDL-数据定义语言(Data Definition Language)
包括动词CREATE和DROP。在数据库中创建新表或删除表(CREAT TABLE 或 DROP TABLE)、为表加入索引等。
-- SQL CREATE TABLE + CONSTRAINT 语法
CREATE TABLE [table_name]
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
常见数据类型
| SQL Server数据类型 | 占用字节数 | 表示范围 | 对应的CLR类型 | 数据类型选择 | 适用场景 |
|---|---|---|---|---|---|
| char | char(n) | System.String | char(2) | 使用char(2)来表示类型或状态(建议用tinyint代替),长度固定,不管数据长度多少都占用声明大小 | |
| varchar | varchar(n) | 1~8000 | System.String | varchar(20) | 包含英文字符的字符串,注意一个汉字占用两个字节,最多8k字符,4k汉字 |
| nvarchar | nvarchar(n) | 1~4000 | System.String | nvarchar(20) | 包含中文字符的字符串,所有字符均占用两个字节,即中英文最大都是4k长度 |
| int | 4个字节 | -2,147,483,648 到 2,147,483,647 | System.Int32 | int | 表示整型,比如自增ID和表示数量 |
| bigint | 8个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | System.Int64(Long) | bigint | 表示长整型,比如自增ID(数量比较大的情况下) |
| decimal | 5~17字节 | System.Decimal | decimal(18,2) | 金额和價格(和錢相關的) | |
| tinyint | 1字节 | 0~255 | System.Byte | tinyint | 类型和状态,比char(2)扩展性好 |
| bit | 0,1或NULL | System.Boolean | bit | 一般用来表示是和否两种情形,比如IsStop | |
| datetime | 8字节 | 1753 年 1 月 1 日到 9999 年 12 月 31 日 | System.DateTime | datetime | 表示日期和时间 |
| time | System.TimeSpan | time(7) | 表示时间间隔,比如计时和耗時 | ||
| varbinary | System.Byte | varbinary(max) | 表示二进制数据 |
CHAR、VARCHAR、NVARCHAR、TEXT区别
相同的是,这四种类型都可以保存字符串。
- CHAR:适合存储固定长度数据,CHAR字段索引效率极高,但是比如定义CHAR(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间。
- VARCHAR:适合存储变长数据,但存储效率没有CHAR高。从空间上考虑,用VARCHAR合适;从效率上考虑,用char合适。
- NCHAR、NVARCHAR、NTEXT:前面的N表示存储的是Unicode数据类型的字符,也就是英文字符也占用两个字节,在存储英文时数量上有损失。中英文混存可以保证长度不超过4k。
- TEXT:TEXT存储可变长度的非Unicode数据,最大长度为2^31-1(2,147,483,647)个字符。
常见数据约束
| constraint_name | 说明 |
|---|---|
| NOT NULL | 指示某列不能存储 NULL 值。 |
| UNIQUE | 保证某列的每行必须有唯一的值。 |
| PRIMARY KEY | NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。 |
| FOREIGN KEY | 保证一个表中的数据匹配另一个表中的值的参照完整性。 FOREIGN KEY([本表字段]) REFERENCES [主键表](主键字段) |
| CHECK | 保证列中的值符合指定的条件。 |
| DEFAULT | 规定没有给列赋值时的默认值。 |
示例
CREATE TABLE EMP
(
[ID] INT IDENTITY(1,1),--自增长列,是标识,标识种子、增量均为1
[DEPT_ID] INT NULL,--默认约束为null,也可显式写出
[DEPT_NUMBER] VARCHAR(20) UNIQUE,--唯一值约束 varchar(20)最多20个字符,10个汉字
[EMP_DATE] DATETIME NULL,
[PASSWORD] VARCHAR(50) NOT NULL,--非空值约束
[NAME] VARCHAR(50) NOT NULL,
[AGE] INT CHECK([AGE]>18 AND [AGE]<150),
[GENDER] CHAR(2) NULL,
[IS_DEL] BIT DEFAULT(0),--默认值约束
PRIMARY KEY([ID]),--主键约束
FOREIGN KEY([DEPT_ID]) REFERENCES [DEPT]([ID])--外键约束,创建表时就会检查外键表是否有该字段
)
--或者
CREATE TABLE EMP
(
[ID] INT IDENTITY(1,1) PRIMARY KEY,--自增长列,是标识,标识种子、增量均为1
[DEPT_ID] INT NULL FOREIGN KEY REFERENCES [DEPT]([ID]),--默认约束为null,也可显式写出
[DEPT_NUMBER] VARCHAR(20) UNIQUE,--唯一值约束 varchar(20)最多20个字符,10个汉字
[EMP_DATE] DATETIME NULL,
[PASSWORD] VARCHAR(50) NOT NULL,--非空值约束
[NAME] VARCHAR(50) NOT NULL,
[AGE] INT CHECK([AGE]>18 AND [AGE]<150),
[GENDER] CHAR(2) NULL,
[IS_DEL] BIT DEFAULT(0)--默认值约束
)
--删除表,一定要注意,尽量做备份后再删除
DROP TABLE [EMP];
--可以简单备份,只备份基本表结构和数据
SELECT * INTO EMP_20170925 FROM EMP;
针对已经存在的表进行表结构的变更:
-- 在表中添加列
ALTER TABLE table_name ADD column_name datatype;
-- 从表中删除列
ALTER TABLE table_name DROP COLUMN column_name;
1.2.3. DML-数据操作语言(Data Manipulation Language)
包括动词INSERT,UPDATE和DELETE。它们分别用于添加,修改和删除表中的行。
插入数据
--插入数据
INSERT INTO [表名](字段1,字段2,字段3...) VALUES (值1,值2,值3...);
INSERT INTO [表名](字段1,字段2,字段3...) VALUES
(值1,值2,值3...),
(值1a,值2a,值3a...);
--不指定列名也可以,即VALUES后写明所有字段,但不推荐此方式,否则表结构变动时很容易导致bug
INSERT INTO [表名] VALUES (值1,值2,值3...);
更新数据
-- 更新数据
UPDATE [表名] SET 字段1 = 值1, 字段2 = 值2... WHERE 1 = 1 AND 其他条件...;
-- ms sql 中还提供了 UPDATE...SET...FROM...WHERE... 的写法,在UPDATE中使用JOIN
UPDATE A SET A1 = B1, A2 = B2, A3 = B3 FROM A LEFT JOIN B ON A.ID = B.ID;
关于Oracle和MySql中对应的写法,参考:
删除数据
--删除数据
DELETE FROM [表名] WHERE 1 = 0 OR 其他条件...;
TRUNCATE TABLE [表名];
1.2.4. DQL-数据查询语言(Data Query Language)
用以从表中获得数据,确定数据怎样在应用程序给出。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有WHERE,ORDER BY,GROUP BY和HAVING。
投影查询
投影查询,从列的角度,即选择表中全部列或部分列
SELECT * FROM [TABLE_NAME];
SELECT FIELD1, FIELD2, FIELD3... FROM [TABLE_NAME];
--给字段起别名
SELECT FIELD1 AS NEW_NAME1, FIELD2 AS NEW_NAME2, FIELD3 AS NEW_NAME3... FROM [TABLE_NAME];
SELECT FIELD1 NEW_NAME1, FIELD2 NEW_NAME2, FIELD3 NEW_NAME3... FROM [TABLE_NAME];
选择查询
选择查询,从行的角度,通过WHERE关键字筛选行
SELECT * FROM [TABLE_NAME] WHERE FIELD1 = 'XXX';
-- AND/OR/IN/BETWEEN...AND...的使用
SELECT * FROM [TABLE_NAME] WHERE FIELD1 = 'XXX' AND FIELD2 = 'XXXX';
SELECT * FROM [TABLE_NAME] WHERE FIELD1 = 'XXX' OR FIELD2 = 'XXXX';
SELECT * FROM [TABLE_NAME] WHERE FIELD1 IN ('X','XX','XXX');
SELECT * FROM [TABLE_NAME] WHERE FIELD1 BETWEEN 1 AND 3;
-- LIKE 模糊匹配,通配符:百分号(%)是任意数量的未知字符的替身,下划线(_)是一个未知字符的替身
SELECT * FROM [TABLE_NAME] WHERE FIELD1 LIKE '%XXX';
SELECT * FROM [TABLE_NAME] WHERE FIELD1 LIKE 'XXX%';
SELECT * FROM [TABLE_NAME] WHERE FIELD1 LIKE 'XXX_';
-- ORDER BY 排序,默认升序ASC
SELECT * FROM [TABLE_NAME] WHERE FIELD1 = 'XXX' ORDER BY FIELD2 DESC;
聚合查询
聚合查询,对查询做聚合操作,即统计,如何求和,取平均值等
常用聚合函数:
| 语法 | 说明 |
|---|---|
| AVG([DISTINCT]列名) | AVG函数用于计算精确型或近似型数据类型的平均值,bit类型除外,忽略null值。AVG函数计算时将计算一组数的总和,然后除以为null的个数,得到平均值。 |
| COUNT([DISTINCT]列名) | count函数用于计算满足条件的数据项数,返回int数据类型的值。 |
| SUM([DISTINCT]列名) | SUM函数用于求和,只能用于精确或近似数字类型列(bit类型除外),忽略null值 |
| MAX(列名) | MAX函数用于计算最大值,忽略null值。max函数可以使用于numeric、char、varchar、money、smallmoney、或datetime列,但不能用于bit列。 |
| MIN(列名) | MIN函数用于计算最小值,MIN函数可以适用于numeric、char、varchar或datetime、money或smallmoney列,但不能用于bit列。 |
SELECT AVG(FIELD1) FROM [TABLE_NAME];
SELECT COUNT(*) FROM [TABLE_NAME];
SELECT COUNT(1) FROM [TABLE_NAME];
SELECT COUNT(0) FROM [TABLE_NAME];
SELECT SUM(FIELD1) FROM [TABLE_NAME];
SELECT MAX(FIELD1) FROM [TABLE_NAME];
SELECT MIN(FIELD1) FROM [TABLE_NAME];
Count统计
COUNT(*),COUNT(1),COUNT(0) : 无论数据行中是否有NULL值,返回统计均一样。仅当COUNT(列名)时会判断属性值是否为NULL。
CREATE TABLE TABLE_1
(
ID INT,
NAME VARCHAR(20)
)
INSERT INTO TABLE_1 (ID,NAME) VALUES(NULL,'王');
INSERT INTO TABLE_1 (ID,NAME) VALUES(NULL,'张');
SELECT COUNT(*) FROM TABLE_1;--2
SELECT COUNT(1) FROM TABLE_1;--2
SELECT COUNT(NAME) FROM TABLE_1;--2
SELECT COUNT(ID) FROM TABLE_1;--0
GROUP BY
顾名思义group即为分组,即将原来的一整块数据分成几小块。
分组是聚合的前提,聚合是在每个分组内进行一些统计,如在分组内的最大值,最小值,平均值,个数等。
未分组时查询返回的行直接与数据库表中的行对应,分组后分为多少组这个查询就会返回多少条记录,返回的记录中只能包含分组字段和在这个分组上的聚合操作的值。
CREATE TABLE T_USER
(
ID INT IDENTITY(1, 1) ,
NAME VARCHAR(20) ,
AGE INT ,
GENDER CHAR(2)
)
INSERT INTO T_USER ( NAME, GENDER, AGE ) VALUES ( '王', '男', 12 );
INSERT INTO T_USER ( NAME, GENDER, AGE ) VALUES ( '张', '女', 18 );
INSERT INTO T_USER ( NAME, GENDER, AGE ) VALUES ( '张', '女', 20 );
INSERT INTO T_USER ( NAME, GENDER, AGE ) VALUES ( '张', '女', 22 );
INSERT INTO T_USER ( NAME, GENDER, AGE ) VALUES ( '王', '女', 9 );
在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
HAVING子句
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
--按列找出重复的数据,并统计重复的数目
SELECT NAME,COUNT(NAME) CNT FROM T_USER GROUP BY NAME HAVING COUNT(NAME) > 1;
1.2.5. 多表查询
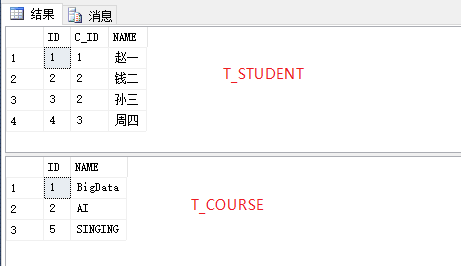
连接JOIN
CREATE TABLE T_STUDENT
(
ID INT NOT NULL ,
C_ID INT ,
NAME VARCHAR(20)
);
CREATE TABLE T_COURSE ( ID INT, NAME VARCHAR(20) );
INSERT INTO dbo.T_STUDENT
( ID, C_ID, NAME )
VALUES ( 1, 1, '赵一'),(2,2,'钱二'),(3,2,'孙三'),(4,3,'周四');
INSERT INTO dbo.T_COURSE
( ID, NAME )
VALUES ( 1, 'BigData'),(2,'AI'),(5,'SINGING')
数据如下所示:
-- 笛卡尔积 cross join
-- 左连接 left join 或 left outer join
-- 右连接 right join 或 right outer join
-- 内连接 join 或 inner join
-- 全外连接 full join 或 full outer join
合并UNION
将多个结果集进行合并,使用关键字时候 UNION [ALL],有以下需要注意的地方:
- 两个结果集的数据列数量和数据类型必须保持一致;
- 如果有ALL则不会移除重复的行,也不会自动排序,仅仅做合并操作;
EXCEPT 和 INTERSECT
EXCEPT是指在第一个集合中存在,但是不存在于第二个集合中的数据。
INTERSECT是指在两个集合中都存在的数据。
以下是将使用 EXCEPT 或 INTERSECT 的两个查询的结果集组合起来的基本规则:
- 所有查询中的列数和列的顺序必须相同。
- 数据类型必须兼容。
-- 左侧中排除右侧数据
( SELECT 12 AS ID ,
'jack' AS NAME
UNION ALL
SELECT 11 ,
'lucy'
)
EXCEPT
( SELECT 11 ,
'lucy'
)
-- 两个集合交集
( SELECT 12 AS ID ,
'jack' AS NAME
UNION ALL
SELECT 11 ,
'lucy'
)
INTERSECT
( SELECT 11 ,
'lucy'
)
1.2.6. 用法拓展
DISTINCT
用于返回唯一不同的值。
-- 返回不同的FIELD1值
SELECT DISTINCT FIELD1 FROM [TABLE_NAME];
-- 返回不同的FIELD1,FIELD2值
SELECT DISTINCT FIELD1, FIELD2 FROM [TABLE_NAME];
-- 也可以搭配聚合函数使用,统计不同FIELD1字段值的数目
SELECT COUNT(DISTINCT FIELD1) FROM [TABLE_NAME];
TOP
TOP 子句用于规定要返回的记录的数目。
--返回前10行数据
SELECT TOP 10 * FROM [TABLE_NAME];
-- 返回前10%的数据
SELECT TOP 10 PERCENT * FROM [TABLE_NAME];
--拓展-随机返回10行数据,NEWID()生成随机数,每次生成随机数进行排序既是随机返回数据
SELECT TOP 10 * FROM [TABLE_NAME] ORDER BY NEWID();
INSERT INTO...SELECT...
用于已存在的表的数据拷贝,可以指定列进行拷贝。
-- 将TABLE_1中COLUMN_1,COLUMN_2拷贝到TABLE_2中的FIELD_1,FIELD_2,相当于往TABLE_2插入数据
INSERT INTO TABLE_2(FIELD_1,FIELD_2) SELECT COLUMN_1,COLUMN_2 FROM TABLE_1;
SELECT...INTO..
用于不存在的表,将数据从一个表导入另一个表,可以指定列。常用于表备份和记录存档。
注意,这种方式不会保存主键、索引等信息。
-- 将表TABLE_NAME中数据拷贝到新表TABLE_NAME_2017,适用于不存在该表结构的拷贝
SELECT * INTO [TABLE_NAME_2017] FROM [TABLE_NAME];
CASE...WHEN...
条件判断语句,用于数据库中信息的转换。Oracle中不仅有CASE...WHEN...还有更方便使用的DECODE()
有两种写法,如下示例:
SELECT CASE
WHEN FIELD_1 = 1 THEN 'A'
WHEN FIELD_1 = 2 THEN 'B'
ELSE 'OTH' END AS NEW_FIELD
FROM TABLE_NAME;
--和上面方式是等价的
SELECT CASE FIELD_1
WHEN 1 THEN 'A'
WHEN 2 THEN 'B'
ELSE 'OTH' END AS NEW_FIELD
FROM TABLE_NAME;
SELECT XXX()
需要测试某函数返回值,或者计算某值的时候,可以直接使用SELECT,而不加FROM。
--查看当前系统时间
SELECT SYSDATETIME();
--计算表达式的值
SELECT 1+1 ;
IN和Exists
总结:
SELECT * FROM 大表 WHERE FIELD_X IN (SELECT FIELD_X FROM 小表);
SELECT * FROM 小表 WHERE EXISTS (SELECT * FROM 大表 WHERE 大表.xx = 小表.xx);
WITH AS
WITH AS短语,也叫做子查询部分(subquery factoring),可以定义一个SQL片断,该SQL片断会被整个SQL语句用到。
下例为经典案例的查询学生成绩SQL:
SELECT *
FROM dbo.SC
WHERE Sno IN ( SELECT sno
FROM dbo.Student
WHERE Sname LIKE '%李%' );
虽然上例中子查询部分的SQL很简单,仅做了一次模糊查询,但是如果嵌套层次过多,条件复杂的情况,会使SQL语句非常难以阅读和维护。
为此,在SQL Server 2005中提供了另外一种解决方案,这就是公用表表达式(CTE),使用CTE,可以使SQL语句的可维护性,同时,CTE要比表变量的效率高得多。
语法如下:
[ WITH <common_table_expression> [ ,n ] ]
<common_table_expression>::=
expression_name [ ( column_name [ ,n ] ) ]
AS
( CTE_query_definition )
针对上述示例查询学生成绩可以进行优化(此案例虽然看上去使用CTE更复杂,但是在复杂场景下使用CTE能很大程度的使SQL结构清晰):
WITH temp
AS ( SELECT sno
FROM dbo.Student
WHERE Sname LIKE '%李%'
)
SELECT *
FROM dbo.SC
WHERE Sno IN ( SELECT *
FROM temp );
开窗函数
OVER 子句定义查询结果集内的窗口或用户指定的行集。 然后,开窗函数将计算窗口中每一行的值。
在ISO SQL规定了这样的函数为开窗函数,在Oracle中则被称为分析函数,而在DB2中则被称为OLAP函数。
开窗函数与聚合函数一样,都是对行的集合组进行聚合计算。
它用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
调用格式为:函数名(列) OVER(选项)
语法:OVER ( [ PARTITION BY value_expression ] [ order_by_clause ] )
第一大类:聚合开窗函数====》聚合函数(列) OVER (选项),这里的选项可以是PARTITION BY子句,但不可是ORDER BY子句
CREATE TABLE t_product
(
ProductID INT ,
ProductName VARCHAR(20) ,
ProductType VARCHAR(20) ,
Price INT
)
INSERT dbo.t_product VALUES (1 ,'name1' ,'P1' ,3)
INSERT dbo.t_product VALUES (2 ,'name2' ,'P1' ,5)
INSERT dbo.t_product VALUES (3 ,'name3' ,'P2' ,4)
INSERT dbo.t_product VALUES (4 ,'name4' ,'P2' ,4)
找出价格最高产品的信息:
SELECT a.*
FROM dbo.t_product a
JOIN ( SELECT ProductType ,
MAX(Price) Price
FROM dbo.t_product
GROUP BY ProductType
) pmax ON a.ProductType = pmax.ProductType
WHERE a.Price = pmax.Price
ORDER BY a.ProductType
利用over(),将统计信息计算出来,然后直接筛选结果集。
WITH pmax
AS ( SELECT a.* ,
MAX(a.Price) OVER ( PARTITION BY a.ProductType ) MaxPrice
FROM dbo.t_product a
)
SELECT *
FROM pmax
WHERE pmax.Price = pmax.MaxPrice
添加【所在分类产品数目】统计信息:
SELECT a.* ,
COUNT(a.ProductID) OVER ( PARTITION BY a.ProductType ) AS "所在分类产品数目"
FROM dbo.t_product a;
第二大类:排序开窗函数====》排序函数(列) OVER(选项),这里的选项可以是ORDER BY子句,也可以是 OVER(PARTITION BY子句 ORDER BY子句),但不可以是PARTITION BY子句
查询每个产品分类内的价格排名,并按照升序显示:
-- ROW_NUMBER()为每一组的行按顺序生成一个唯一的序号,结合OVER()开窗实现
SELECT a.* ,
ROW_NUMBER() OVER ( PARTITION BY a.ProductType ORDER BY a.Price ) AS "组内排名"
FROM dbo.t_product a
ORDER BY a.Price;
PIVOT和UNPIVOT
- PIVOT
通过将表达式某一列中的唯一值转换为输出中的多个列来旋转表值表达式,并在必要时对最终输出中所需的任何其余列值执行聚合。即将列值旋转为列名(即行转列)
一般语法是:PIVOT(聚合函数(值-列) FOR pivot-列 in (值1,值2,值3...) )AS P
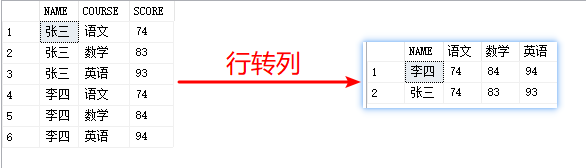
以上即行转列的示例,对应的sql脚本如下:
-- 构建测试表 用以模拟
IF OBJECT_ID('T_SCORE') IS NOT NULL DROP TABLE T_SCORE
GO
CREATE TABLE T_SCORE(NAME VARCHAR(10),COURSE VARCHAR(10),SCORE INT)
INSERT INTO T_SCORE VALUES('张三','语文',74)
INSERT INTO T_SCORE VALUES('张三','数学',83)
INSERT INTO T_SCORE VALUES('张三','英语',93)
INSERT INTO T_SCORE VALUES('李四','语文',74)
INSERT INTO T_SCORE VALUES('李四','数学',84)
INSERT INTO T_SCORE VALUES('李四','英语',94)
GO
--使用CASE WHEN 的方式进行行转列
SELECT NAME
,MAX((CASE WHEN COURSE = '语文' THEN SCORE ELSE NULL END )) AS 语文
,MAX((CASE WHEN COURSE = '数学' THEN SCORE ELSE NULL END )) AS 数学
,MAX((CASE WHEN COURSE = '英语' THEN SCORE ELSE NULL END )) AS 英语
FROM T_SCORE GROUP BY NAME;
--简单的示例,没有包含其他字段的情况下。除去[SCORE]和[COURSE]字段进行GROUP BY
SELECT * FROM T_SCORE PIVOT(MAX(SCORE) FOR COURSE IN (语文,数学,英语) ) AS P;
实际生产案例中比上述情况要复杂的多,在使用PIVOT转换前我们需要先进行投影,否则PIVOT进行分组得到的并不是我们需要的结果:
--修改测试表结构,添加测试字段
ALTER TABLE T_SCORE ADD REMARK VARCHAR(100);
GO
--更新值,模拟测试
UPDATE T_SCORE SET REMARK = NAME + COURSE;
--多字段,较复杂情况的处理,需要在投影的基础上进行PIVOT
SELECT * FROM (SELECT NAME,COURSE,SCORE FROM T_SCORE ) T PIVOT(MAX(SCORE) FOR COURSE IN (语文,数学,英语)) AS P;
- UNPIVOT
将表值表达式的列转换为列值。
一般语法是:UNPIVOT(值-列 FOR pivot-列 IN (列1,列2,列3...)) AS P

-- 构建测试表 用以模拟
IF OBJECT_ID('T_SCORE_EX') IS NOT NULL DROP TABLE T_SCORE_EX
GO
CREATE TABLE T_SCORE_EX(NAME VARCHAR(10),[语文] INT,[数学] INT,[英语] INT)
INSERT INTO T_SCORE_EX VALUES('张三',74,83,93)
INSERT INTO T_SCORE_EX VALUES('李四',74,84,94)
GO
--采用union的方式进行列转行
SELECT NAME,'语文' AS [课程],[语文] AS [分数] FROM T_SCORE_EX
UNION ALL
SELECT NAME,'数学',[数学] FROM T_SCORE_EX
UNION ALL
SELECT NAME,'英语',[英语] FROM T_SCORE_EX ;
--UNPIVOT 列转换行
SELECT * FROM T_SCORE_EX T UNPIVOT ([分数] FOR [课程] IN ([语文],[数学],[英语])) AS P ;
ps.对升级到 SQL Server 2005 或更高版本的数据库使用 PIVOT 和 UNPIVOT 时,必须将数据库的兼容级别设置为 90 或更高。
1.2.7. 常用函数
类型转换
在SQL SERVER中,cast和convert函数都可用于类型转换,其功能是相同的,只是语法不同。
CAST ( expression AS data_type [ ( length ) ] )
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
cast一般更容易使用,convert的优点是可以格式化日期和数值,如下案例:
select CAST('123' as int) -- 123
select CONVERT(int, '123') -- 123
select CAST(123.4 as int) -- 123
select CONVERT(int, 123.4) -- 123
select CAST('123.4' as int)
select CONVERT(int, '123.4')
-- Conversion failed when converting the varchar value '123.4' to data type int.
select CAST('123.4' as decimal) -- 123
select CONVERT(decimal, '123.4') -- 123
select CAST('123.4' as decimal(9,2)) -- 123.40
select CONVERT(decimal(9,2), '123.4') -- 123.40
declare @Num money
set @Num = 1234.56
select CONVERT(varchar(20), @Num, 0) -- 1234.56
select CONVERT(varchar(20), @Num, 1) -- 1,234.56
select CONVERT(varchar(20), @Num, 2) -- 1234.5600
-- 时间格式,还有很多其他格式
SELECT CONVERT(VARCHAR,GETDATE(),120); -- 2018-03-29 23:18:23
SELECT CONVERT(VARCHAR,GETDATE(),121); -- 2018-03-29 23:18:23.810
SELECT CONVERT(VARCHAR,GETDATE(),111); -- 2018/03/29
SELECT CONVERT(VARCHAR,GETDATE(),112); -- 20180329
字符串操作
-- STR() 把数值型数据转换为字符型数据。
SELECT STR(123);
-- LOWER() UPPPER() 大小写转换
SELECT LOWER('Hello World');
SELECT UPPER('Hello World');
-- LTRIM() 把字符串头部的空格去掉。
-- RTRIM() 把字符串尾部的空格去掉。
SELECT 'a' + LTRIM(' b ') + 'c';
SELECT 'a' + RTRIM(' b ') + 'c';
-- LEFT (<character_expression>, <integer_expression>)
-- RIGHT (<character_expression>, <integer_expression>)
-- SUBSTRING (<expression>, <starting_ position>, length)
SELECT LEFT('HelloWorld', 5);
SELECT RIGHT('HelloWorld', 5);
SELECT SUBSTRING('HelloWorld', 2, 2);
-- CHARINDEX (<'substring_expression'>, <expression>) substring _expression 是所要查找的字符表达式。如果没有发现子串,则返回0 值。
SELECT CHARINDEX('ello', 'HelloWorld');
-- REPLACE(<expression>,<old_string>,<new_string>)
SELECT REPLACE('HelloWorld', 'l', '=');
日期时间
-- 缺省模式返回当前日期和时间,DateTime类型,yyyy-MM-dd HH:mm:ss.fff ,3个f,精确到1毫秒(ms)
SELECT GETDATE();
-- 当前系统时间,DateTime2类型 yyyy-MM-dd HH:mm:ss.fffffff ,7个f,精确到0.1微秒(μs)
SELECT SYSDATETIME();
-- 返回日期,多少号
SELECT DAY(GETDATE());
-- 返回月份
SELECT MONTH(GETDATE());
-- 返回年份
SELECT YEAR(GETDATE());
1.2.8. 其他语句
- 事务处理语言(TPL)
确保被DML语句影响的表的所有行及时得以更新。TPL语句包括BEGIN TRANSACTION,COMMIT和ROLLBACK。
- 数据控制语言(DCL)
通过GRANT或REVOKE获得许可,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
- 指针控制语言(CCL)
像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
1.2.9. 提高效率RedPrompt
Sql Prompt下载及安装破解图文教程
1.3. 索引
1.3.1. 什么是索引?
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度。
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍。
SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间。
新华字典例子,我们查一个汉字可以通过拼音也可以通过笔画来进行查询,那么这样通过目录的查询方式就是一种索引思想,大大提高了查询效率。
按照拼音查询时,和字典的内容顺序保持一致,相当于聚集索引,同样的一个数据集合顺序是固定的,所以对于一张表而言,只能有一个聚集索引。
按照笔画查询时,笔画顺序和字典内容顺序是不一致的,相当于非聚集索引。
索引的优点主要有以下几条:
- 通过创建唯一索引,可以保证数据库表的每一行数据的唯一性。
- 可以大大加快数据的查询速度,这也是创建索引的最主要的原因。
- 实现数据的参照完整性,可以提高表和表之间连接的效率。
- 在使用分组和排序子句进行查询时,也可以显著减少查询中分组和排序的时间。
带来的一些问题:
- 创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
- 索引需要占磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果有大量的索引,索引文件可能比数据文件更快达到做大文件尺寸。
- 当对表中的数据进行增加,删除和修改的时候,索引也要动态地维护,这样就就降低了数据的维护速度。
1.3.2. 聚集索引(CLUSTERED)
聚集索引基于数据行的键值,在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
- 每个表只能有一个聚集索引;
- 表中的物理顺序和索引中行的物理顺序是相同的,创建任何非聚集索引之前要首先创建聚集索引,这是因为非聚集索引改变了表中行的物理顺序;
- 关键值的唯一性使用UNIQUE关键字或者由内部的唯一标识符明确维护。
- 在索引的创建过程中,SQL Server临时使用当前数据库的磁盘空间,所以要保证有足够的空间创建索引。
1.3.3. 非聚集索引(NONCLUSTERED)
非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页中的数据按列排序,非聚集索引包含索引键值和指向表数据存储位置的行定位器。
可以对表或索引视图创建多个非聚集索引。通常,设计非聚集索引是为了改善经常使用的、没有建立聚集索引的查询的性能。
查询优化器在搜索数据值时,先搜索非聚集索引以找到数据值在表中的位置,然后直接从该位置检索数据。这使得非聚集索引成为完全匹配查询的最佳选择,因为索引中包含搜索的数据值在表中的精确位置的项。
具有以下特点的查询可以考虑使用非聚集索引:
- 使用JOIN或者GROUP BY子句,应为连接和分组操作中所涉及的列创建多个非聚集索引,为任何外键创建一个聚集索引.
- 包含大量唯一值的字段。
- 不返回大型结果集的查询。创建筛选索引以覆盖从大型表中返回定义完善的的行子集的查询。
- 经常包含在查询的搜索条件(如返回完全匹配的WHERE子句)中的列。
1.3.4. 创建索引
例如员工表EMP中需要经常按照[NAME]进行查询的话,则需要针对[NAME]添加索引
-- UNIQUE表示唯一索引,可选
-- CLUSTERED、NONCLUSTERED表示聚集索引还是非聚集索引,可选
-- FILLFACTOR表示填充因子,指定一个0到100之间的值,该值指示索引页填满的空间所占的百分比
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX index_name
ON table_name (column_name…)
[WITH FILLFACTOR=x]
--查看对应表有什么索引
EXEC sp_helpindex 'TABLE_NAME';
--删除对应的索引
DROP INDEX TABLE_NAME.IDX_NAME;
示例中不太容易模拟出巨大的查询差异,我们以实际查询计划作为参考观察有无索引的区别。
如下是一个插入模拟数据的SQL,数据量在500w,存储执行大概在10min多,视机器环境不同而有所区别。
CREATE PROCEDURE [dbo].[SP_BATCH_INSERT]
AS
DECLARE @NUM INT
SET @NUM = 1
IF OBJECT_ID('T_INDEX_TEST') IS NOT NULL
DROP TABLE T_INDEX_TEST
--模拟大数据量表
CREATE TABLE T_INDEX_TEST
(
guid VARCHAR(40) ,
name0 VARCHAR(40) DEFAULT ( NEWID() ) ,
name1 VARCHAR(40) DEFAULT ( NEWID() ) ,
name2 VARCHAR(40) DEFAULT ( NEWID() ) ,
name3 VARCHAR(40) DEFAULT ( NEWID() ) ,
name4 VARCHAR(40) DEFAULT ( NEWID() ) ,
name5 VARCHAR(40) DEFAULT ( NEWID() ) ,
name6 VARCHAR(40) DEFAULT ( NEWID() ) ,
name7 VARCHAR(40) DEFAULT ( NEWID() ) ,
name8 VARCHAR(40) DEFAULT ( NEWID() ) ,
name9 VARCHAR(40) DEFAULT ( NEWID() ) ,
update_time DATETIME DEFAULT ( GETDATE() )
)
--1w * 10 = 10w 条记录
WHILE ( @NUM <= 10000 )
BEGIN
SET @NUM = @NUM + 1
--插入测试数据,NEWID()产生随机值,每次插入10行记录
INSERT INTO T_INDEX_TEST
( guid )
VALUES ( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() ),
( NEWID() )
END
执行完上面的存储后,进行测试:
-- 检测数据量
SELECT count(1) FROM T_INDEX_TEST;
-- 创建副本表,并添加聚集索引,用以对比
SELECT * INTO T_INDEX_TEST_NEW FROM T_INDEX_TEST;
-- 创建副本表的聚集索引 T_INDEX_TEST_NEW
CREATE UNIQUE CLUSTERED INDEX idx_t_index_test_new ON dbo.T_INDEX_TEST(GUID)
-- 取其中一个数据的guid进行查询示例
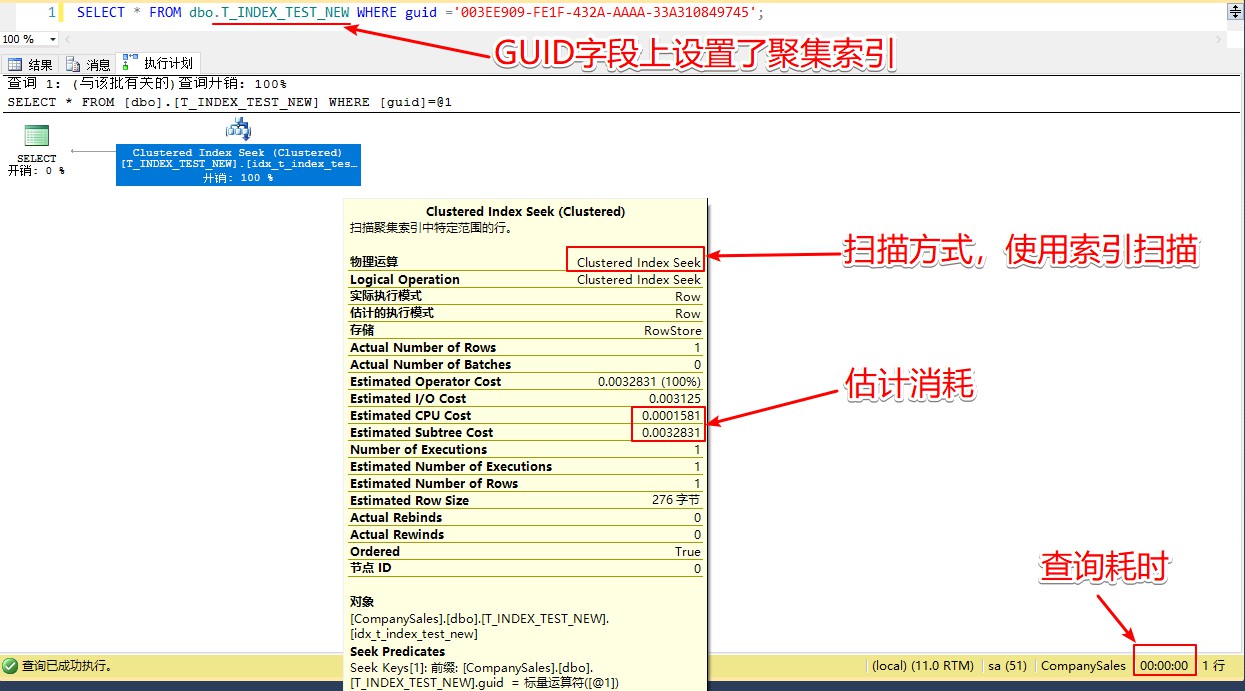
SELECT * FROM dbo.T_INDEX_TEST WHERE guid ='003EE909-FE1F-432A-AAAA-33A310849745';
SELECT * FROM dbo.T_INDEX_TEST_NEW WHERE guid ='003EE909-FE1F-432A-AAAA-33A310849745';
上面案例中,有无索引的直观感受可能并不明显,我们可以通过查看执行计划来对比。
首先,勾选菜单【查询】-【包括实际的执行计划】,然后再进行查询。
下图是针对T_INDEX_TEST无索引的查询:
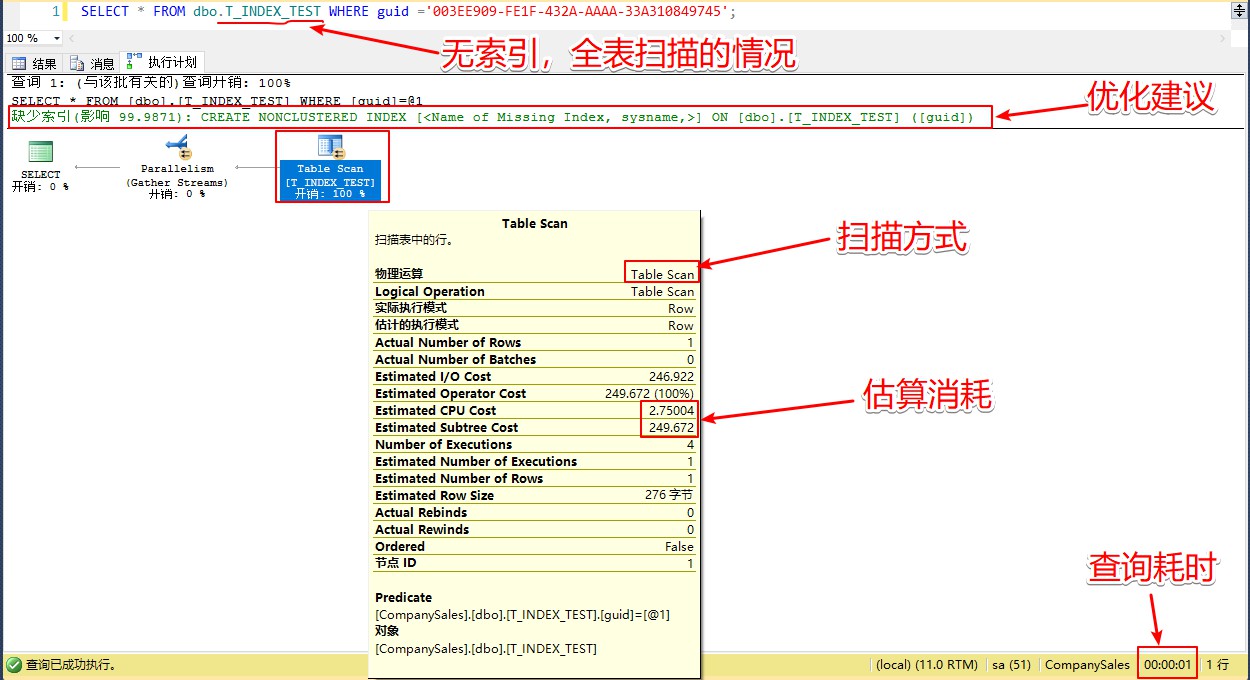
针对GUID有聚集索引的T_INDEX_TEST_NEW查询计划如下:
1.3.5. 索引设计原则
| 场景 | 使用聚集索引 | 使用非聚集索引 |
|---|---|---|
| 外键列 | 推荐 | 推荐 |
| 主键列 | 推荐 | 推荐 |
| order by列 | 推荐 | 推荐 |
| 范围数据列 | 推荐 | 不推荐 |
| 小数目不同值 | 推荐 | 不推荐 |
| 大数目不同值 | 不推荐 | 推荐 |
| 频繁更新列 | 不推荐 | 推荐 |
| 频繁修改索引 | 不推荐 | 推荐 |
| 极少不同值 | 不推荐 | 不推荐 |
索引设计不合理或者缺少索引都会对数据库和应用程序的性能造成障碍,高效的索引对于获得良好的性能非常重要。需要参考以下原则:
- 索引并非越多越好,以空间换取时间,不仅占用空间增加,而且会影响DML语句的效率。表中内容的更改需要索引做出同步修改,例如新华字典的修改。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。
- 对于经常查询的字段需要添加索引,以提高效率。频繁变动的列或频繁更新的表不建议索引过多,索引需要尽可能的少。
- 在存在大量重复值的字段,增加索引没什么太大意义。比如类似性别的字段,只有两种值,使用索引可能造成效率更低。
- 字段里的数据量太大,最好也不要加索引。比如行数据的该字段都保存几百个字符,则添加索引没有意义。
- 外键字段建议添加索引,以增加关联效率
参考引用: